背景
UAE(UC App Engine)是一个UC内部的PaaS平台,总体架构有点类似CloudFoundry,包括:
- 快速部署:支持Node.js、Play!、PHP等框架
- 信息透明:运维过程、系统状态、业务状况
- 灰度试错:IP灰度、地域灰度
- 基础服务:key-value存储、MySQL高可用、图片平台等
这里它不是主角,不作详细介绍。
有数百个Web应用运行在UAE上,所有的请求都会经过UAE的路由,每天的Nginx access log大小是TB级,如何实时监控每个业务的访问趋势、广告数据、页面耗时、访问质量、自定义报表和异常报警?
Hadoop可以满足统计需求,但秒级的实时性不能满足;用Spark Streaming又有些大材小用,同时我们也没有Spark的工程经验;自写分布式程序调度比较麻烦并且要考虑扩展、消息流动;
最后我们的技术选型定为Storm:相对轻量、灵活、消息传递方便、扩展灵活。
另外,而由于UC的各地集群比较多,跨集群日志传输也会是其中一个比较大的问题。
技术准备
基数计数(Cardinality Counting)
在大数据分布式计算的时候,PV(Page View)可以很方便相加合并,但UV(Unique Visitor)不能。
分布式计算的情况下,几百个业务、数十万URL同时统计UV,如果还要分时段统计(每分钟/每5分钟合并/每小时合并/每天合并),内存的消耗是不可接受的。
这个时候,概率的力量就体现了出来。我们在Probabilistic Data Structures for Web Analytics and Data Mining可以看到,精确的哈希表统计UV和基数计数的内存比较,并不是一个数量级的。基数计数可以让你实现UV的合并,内存消耗极小,并且误差完全在可接受范围内。
可以先了解LogLog Counting,理解均匀哈希方法的前提下,粗糙估计的来由即可,后面的公式推导可以跳过。
具体算法是Adaptive Counting,使用的计算库是stream-2.7.0.jar。
实时日志传输
实时计算必须依赖于秒级的实时日志传输,附加的好处是可以避免阶段性传输引起的网络拥堵。
实时日志传输是UAE已有的轻量级的日志传输工具,成熟稳定,直接拿来用了,包括客户端(mca)和服务器端(mcs)。
客户端监听各个集群的日志文件的变化,传输到指定的Storm集群的各台机器上,存储为普通日志文件。
我们调整了传输策略,使得每台Storm机器上的日志文件大小大致相同,所以Spout只读取本机数据即可。
数据源队列
我们并没有用Storm常用的队列,如Kafka、MetaQ等,主要是太重了…
fqueue是一个轻量的memcached协议队列,把普通的日志文件转为memcached的服务,这样Storm的Spout就可以直接以memcached协议逐条读取。
这个数据源比较简单,它不支持重新发射(replay),一条记录被取出之后就不复存在,如果某个tuple处理失败或超时,则数据丢失。
它比较轻量,基于本地文件读取,做了一层薄的缓存,并不是一个纯内存的队列,它的性能瓶颈在于磁盘IO,每秒吞吐量跟磁盘读取速度是一致的。但对于我们这个系统已经足够,后续有计划改成纯内存队列。
架构
通过上面的技术储备,我们可以在用户访问几秒后就能获取到用户的日志。
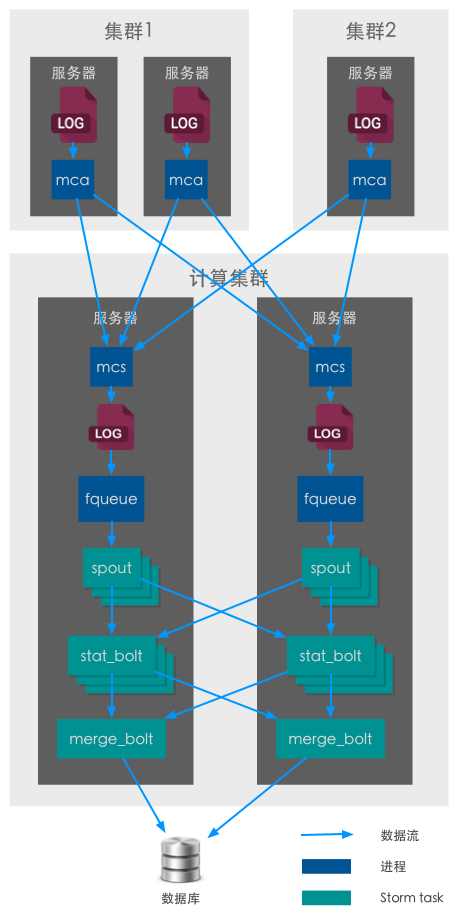
整体架构也比较简单,之所以有两种计算bolt,是基于计算的均匀分布考虑。业务的量相差极大,如果仅按业务ID去进行fieldsGrouping,计算资源也会不均衡。(文章来源 www.pms.cc)
- spout将每条原始日志标准化,按照URL分组(fieldsGrouping,为保持每台服务器计算量的均匀),派发到对应的stat_bolt上;
- stat_bolt是主要的计算Bolt,将每个业务的URL梳理并计算,如PV、UV、总响应时间、后端响应时间、HTTP状态码统计、URL排序、流量统计等;
- merge_bolt将每个业务的数据合并,如PV数,UV数等。当然,这里的UV合并就用到了前面提到的基数计数;
- 自写了一个简单的Coordinator协调类,streamId标记为”coordinator”,作用:时间协调(切分batch)、检查任务完成度、超时处理。原理跟Storm自带的Transactional Topolgoy类似。
- 实现一个Scheduler通过API获取参数,动态调整Spout、Bolt在各服务器的分布,以便灵活分配服务器资源。
- 支持平滑升级Topology:当一个Topology升级的时候,新Topology和旧Topology讲同时运行,协调切换时间,当新的Topology接管了fqueue之后,过河拆桥,杀死旧的Topology。
注意点:
- Storm机器尽量部署在同一个机柜内,不影响集群内的带宽;
- 我们的Nginx日志是按小时切分的,如果切分的时间不准确,在00分的时候,就可以看到明显的数据波动,所以,尽量使用Nginx module去切日志,用crontab发信号切会有延迟。切日志这种10秒级的延迟,在大尺度的统计上没有问题,秒级的统计时波动却很明显;
- 堆太小会导致woker被强制杀死,所以要配置好-Xmx参数;
自定义项
- 静态资源:静态资源过滤选项,通过Content-Type或后缀筛选特定的静态资源。
- 资源合并:URL合并,比如RESTful的资源,合并后方便展示;
- 维度与指标:通过ANTLR v3做语法、词法分析,完成自定义维度和指标,并且后续的报警也支持自定义表达式。
其他
我们还用其他方式实现了:
- 业务的进程级(CPU/MEM/端口)监控
- 业务依赖的服务,如MySQL/memcached等的监控
- 服务器的磁盘/内存/IO/内核参数/语言环境/环境变量/编译环境等监控